PIE: Perception and Interaction Enhanced End-to-End Motion Planning for Autonomous Driving
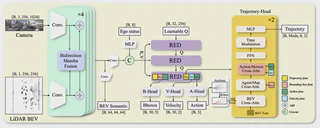 Image credit: Unsplash
Image credit: UnsplashAbstract
End-to-end motion planning is promising for simplifying complex autonomous driving pipelines. However, challenges such as scene understanding and effective prediction for decision-making continue to present substantial obstacles to its large-scale deployment. In this paper, we present PIE, a pioneering framework that integrates advanced perception, reasoning, and intention modeling to dynamically capture interactions between the ego vehicle and surrounding agents. It incorporates a bidirectional Mamba fusion that addresses data compression losses in multimodal fusion of camera and LiDAR inputs, alongside a novel reasoning-enhanced decoder integrating Mamba and Mixture-of-Experts to facilitate scene- compliant anchor selection and optimize adaptive trajectory inference. PIE adopts an action-motion interaction module to effectively utilize state predictions of surrounding agents to refine ego planning. The proposed framework is thoroughly validated on the NAVSIM benchmark. PIE, without using any ensemble and data augmentation techniques, achieves an 88.9 PDM score and 85.6 EPDM score, surpassing the performance of prior state-of-the-art methods. Comprehensive quantitative and qualitative analyses demonstrate that PIE is capable of reliably generating feasible and high-quality ego trajectories.
Type
This work is driven by the results in my previous paper.
Note
Create your slides in Markdown - click the Slides button to check out the example.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.